
Earth observation increasingly relies on multiple sensors — optical, radar, elevation, and land-cover products. Relationships between these modalities are fundamental for data integration, yet they are inherently non-injective: identical conditioning information can correspond to many physically plausible observations and should therefore be parameterised as conditional distributions. Deterministic models, by contrast, collapse toward conditional means and fail to represent the variability required for tasks such as data completion and cross-sensor translation.
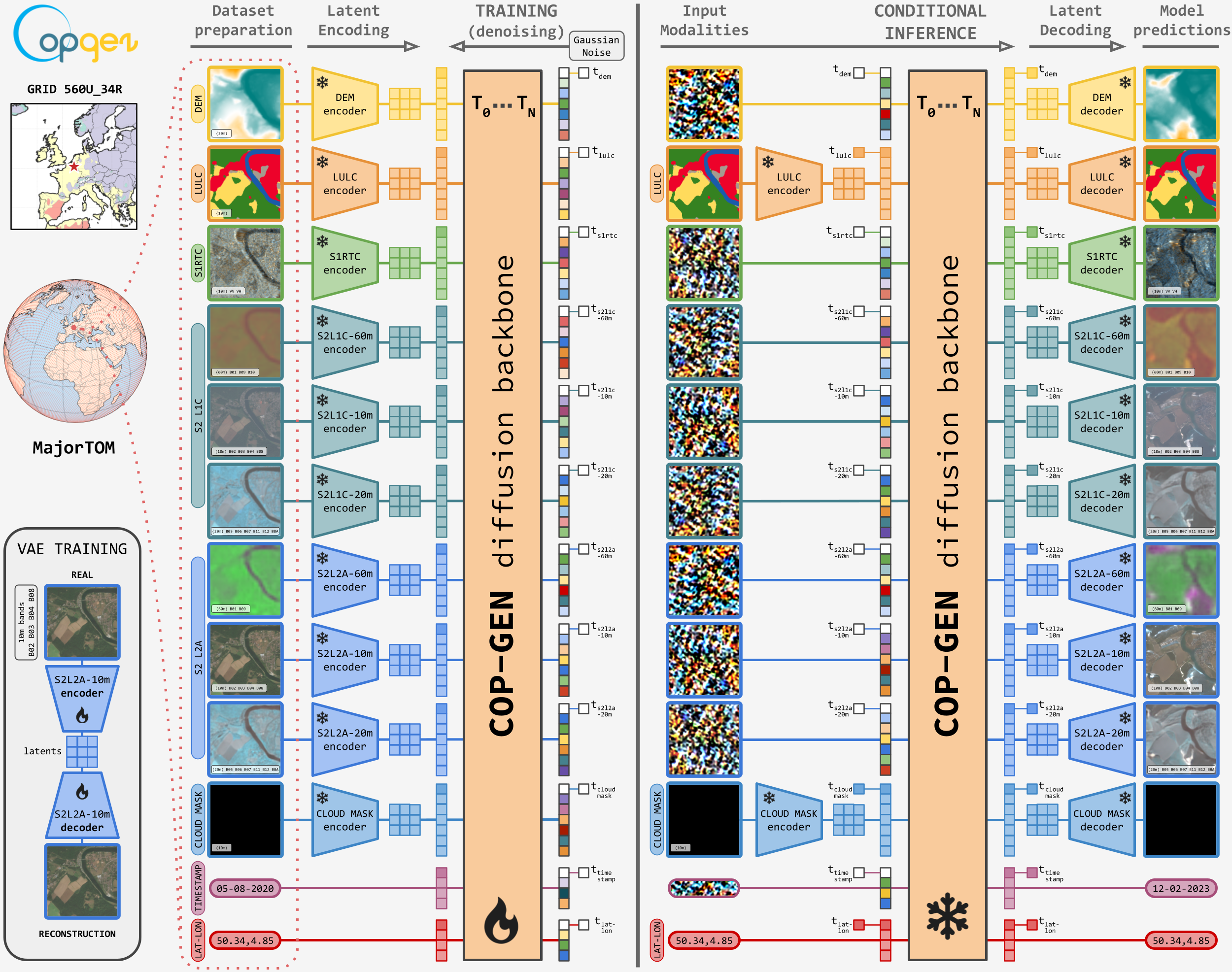
We introduce COP-GEN, a multimodal latent diffusion transformer that models the joint distribution of heterogeneous Earth observation modalities at their native spatial resolutions. By parameterising cross-modal mappings as conditional distributions, COP-GEN enables flexible any-to-any conditional generation — zero-shot modality translation, spectral band infilling, and generation under partial or missing inputs — without task-specific retraining.
On a large-scale global multimodal dataset, COP-GEN generates diverse yet physically consistent realisations while maintaining strong peak fidelity, and systematically narrows its output uncertainty as conditioning becomes more informative. We further release a stochastic benchmark built from multi-temporal Sentinel-2 observations for distribution-level comparison of generative EO models. On this benchmark, COP-GEN covers 90% of the real observation manifold and 63% of its per-band reflectance range, while the strongest competing method collapses to 2.8% and 18%, respectively.
Relationships between Earth observation modalities are inherently non-injective: identical conditioning information—such as terrain elevation or land-cover class—can correspond to multiple physically plausible observations. Such mappings are inherently one-to-many, as shown in Figure 1.
Existing multimodal Earth observation models are typically deterministic—given the same input conditions, they always produce the same output. Models optimized to minimize pointwise error against a single ground truth inevitably regress toward conditional means, suppressing variability that is physically relevant and present in real-world observations.
Stochastic generative modeling provides an alternative route. By learning joint probability distributions across sensors, generative models can estimate multiple physically plausible realisations of a scene conditioned on a subset of input modalities. This approach aligns with remote sensing practice, where environmental processes are dynamic, observations are most often incomplete, and many different outputs are valid.
COP-GEN is a unified multimodal generative model that combines modality-specific latent encoders with a shared transformer-based diffusion backbone. It operates on six modalities at their native resolutions:
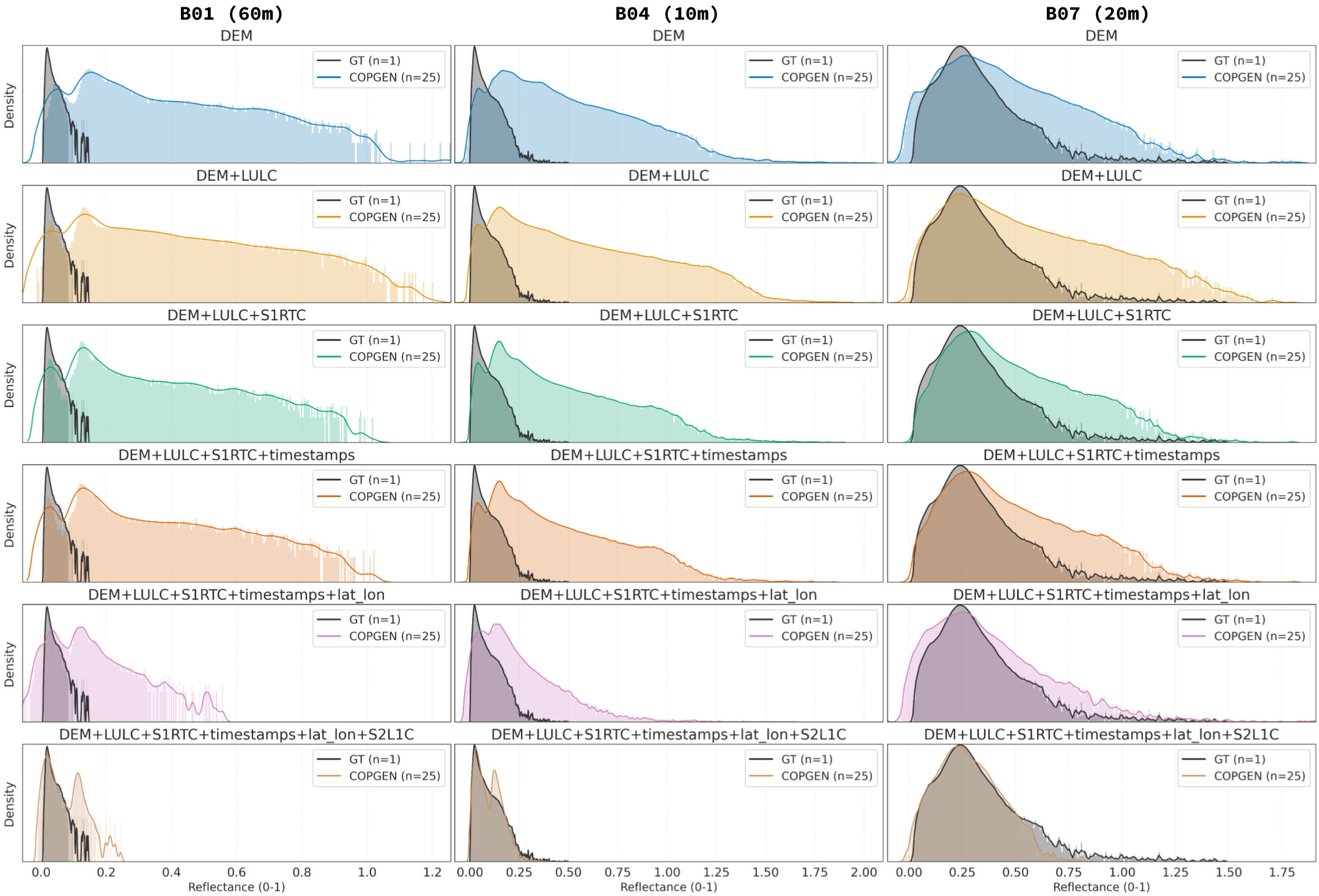
As more conditioning modalities are provided, COP-GEN appropriately narrows its output distribution. Starting from DEM-only conditioning, we incrementally add LULC, S1 RTC, timestamps, and geolocation. The generated spectral distributions systematically converge toward the ground truth.
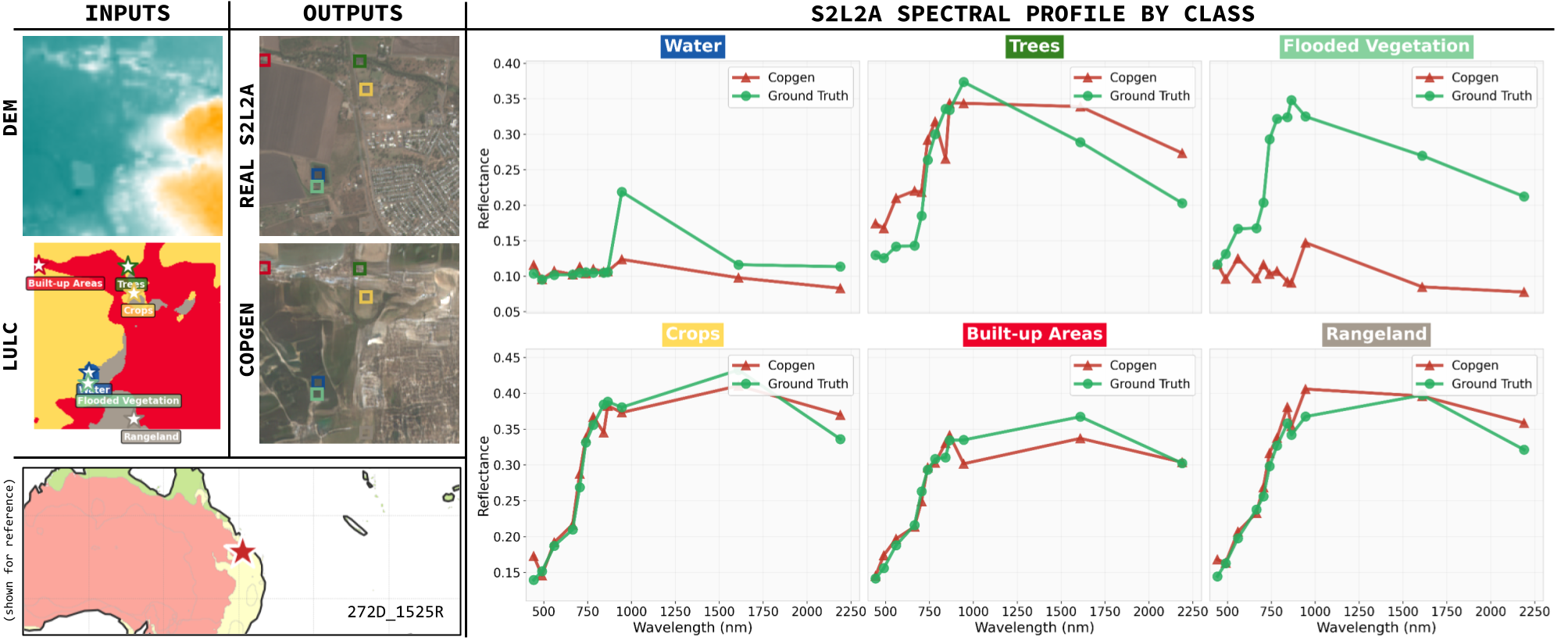
COP-GEN learns physically meaningful spectral relationships. Per-pixel spectral responses closely match the characteristic signatures of different land-cover types across all Sentinel-2 bands.
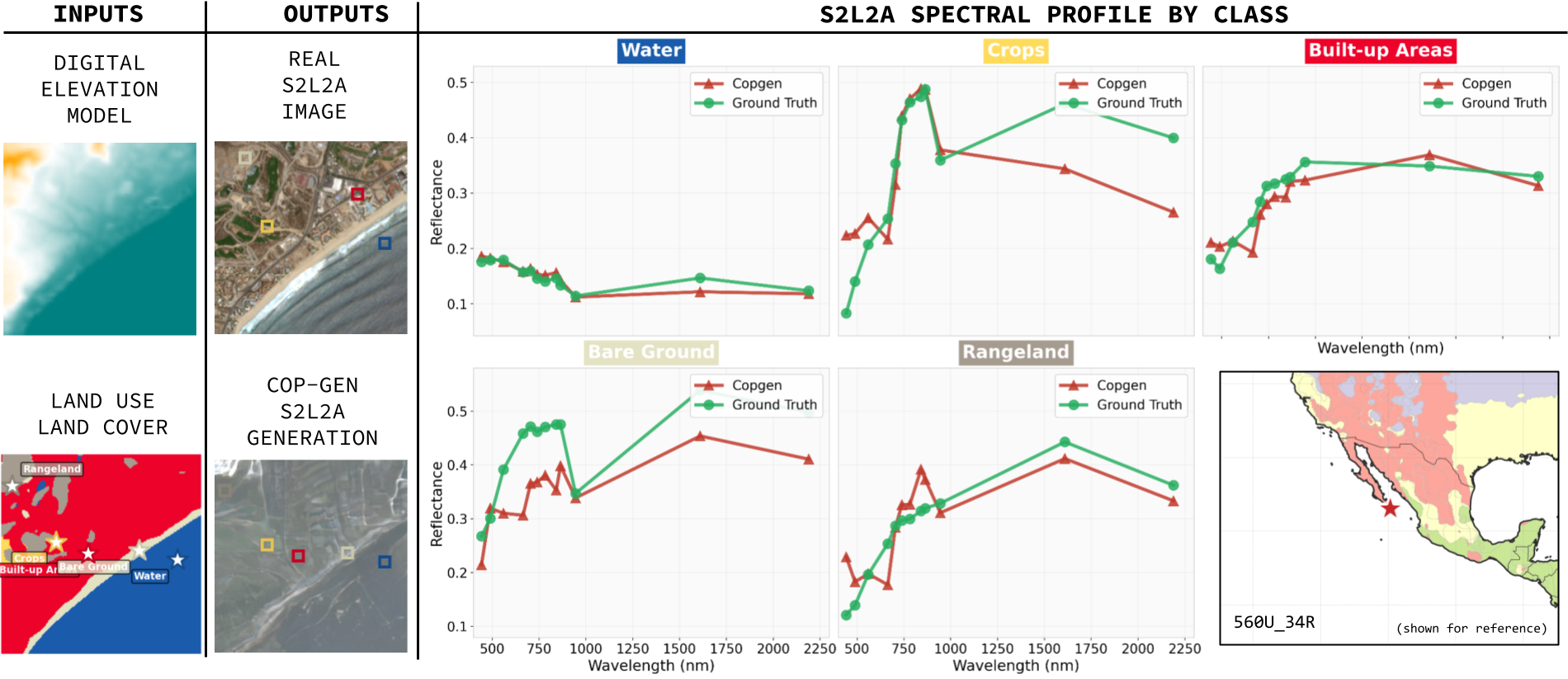
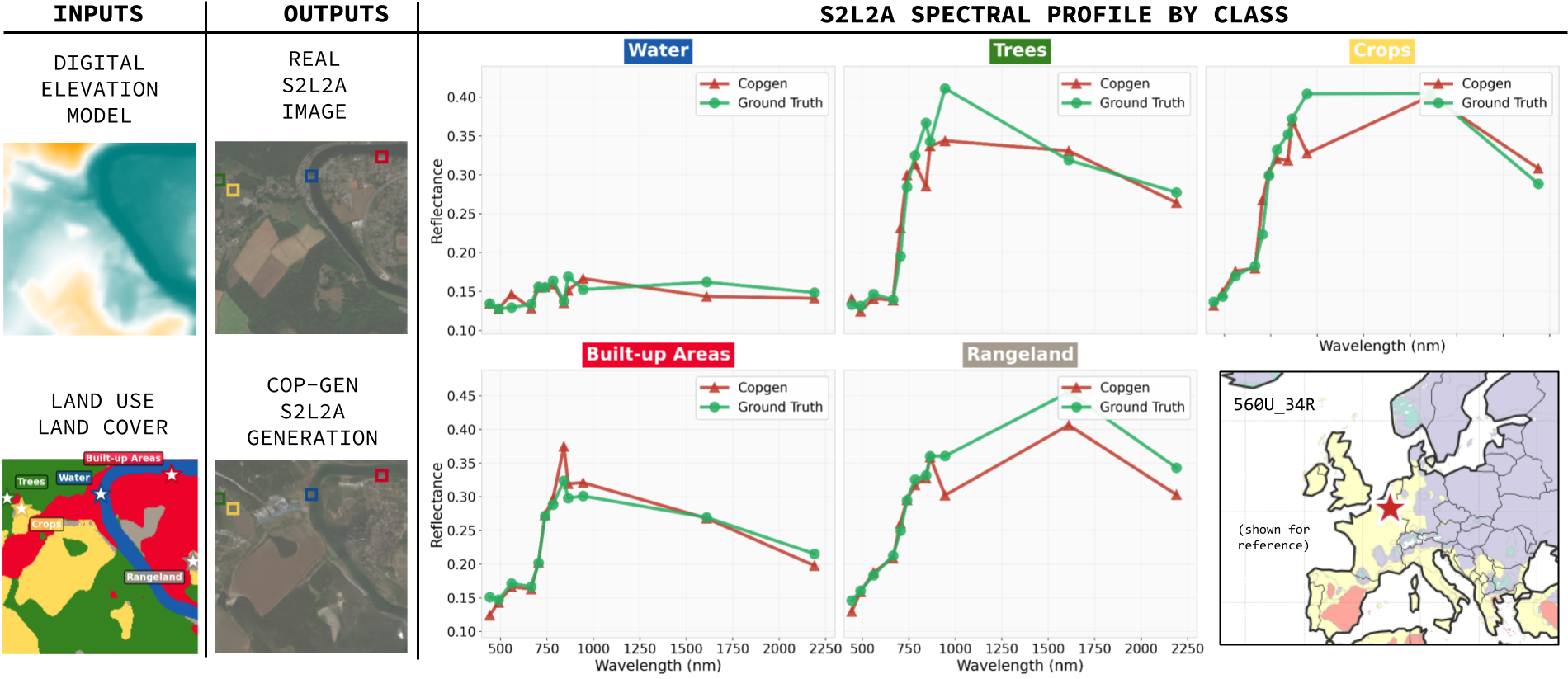
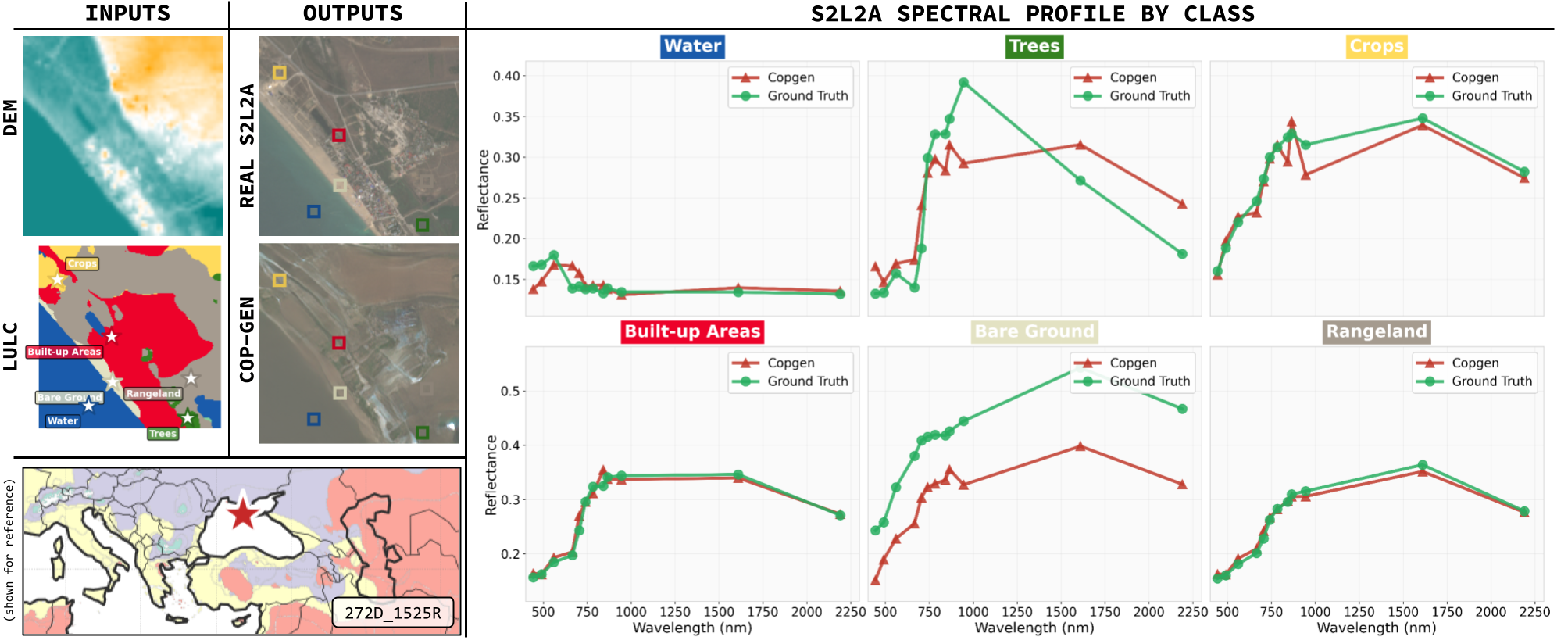
COP-GEN can also perform band infilling — generating missing spectral bands given a subset of available bands. This is useful for completing incomplete observations or synthesizing bands that were not captured by the sensor.

Additional examples of DEM + LULC → Sentinel-2 L2A generation, demonstrating COP-GEN's ability to produce diverse, high-quality outputs across different geographic regions and land-cover types.








We adopt a Peak-Capability (oracle) evaluation protocol: for each test tile, we generate multiple independent samples and report the best-matching generation. This isolates the model's representational capacity from stochastic variance and answers: does the model's learned distribution contain high-fidelity realisations consistent with the ground truth? The complementary distribution-level question — does the full set of generated samples match the distribution of plausible real observations? — is addressed by our Stochastic Benchmark below.
| Target | Metric | Peak perf. (Best per Tile) | |
|---|---|---|---|
| COP-GEN | TerraMind | ||
| DEM | MAE | 26.80 | 145.62 |
| SSIM | 0.45 | 0.44 | |
| LULC | Top-1 | 0.84 | 0.80 |
| mIoU | 0.42 | 0.55 | |
| S1RTC | MAE | 2.63 | 2.64 |
| PSNR | 16.83 | 19.65 | |
| S2L1C | MAE | 0.02 | 0.11 |
| PSNR | 21.16 | 12.77 | |
| S2L1C† | MAE | 0.05 | 0.12 |
| PSNR | 13.92 | 12.68 | |
| S2L2A | MAE | 0.02 | 0.10 |
| PSNR | 22.47 | 17.46 | |
| S2L2A‡ | MAE | 0.06 | 0.10 |
| PSNR | 14.40 | 16.18 | |
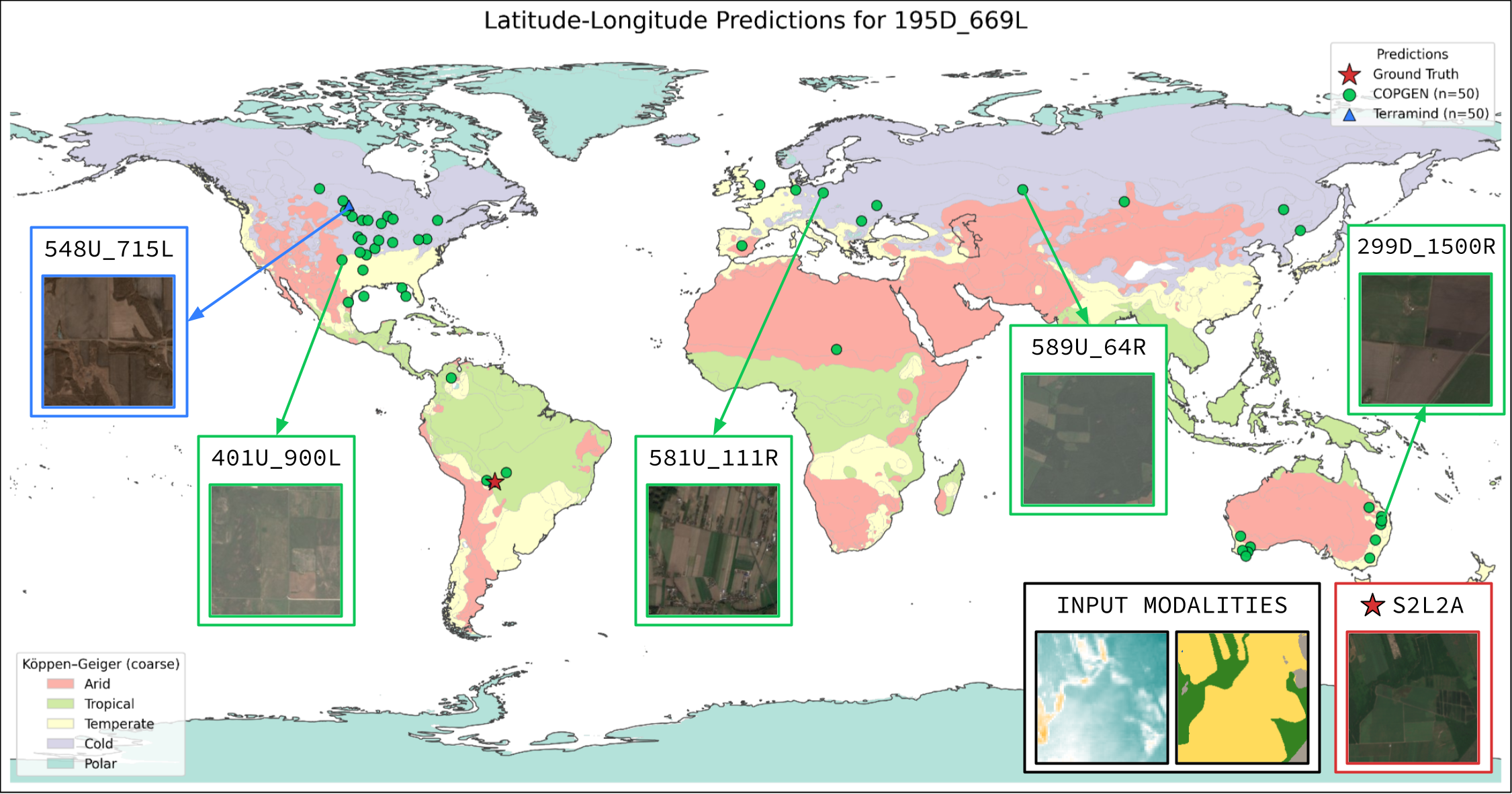
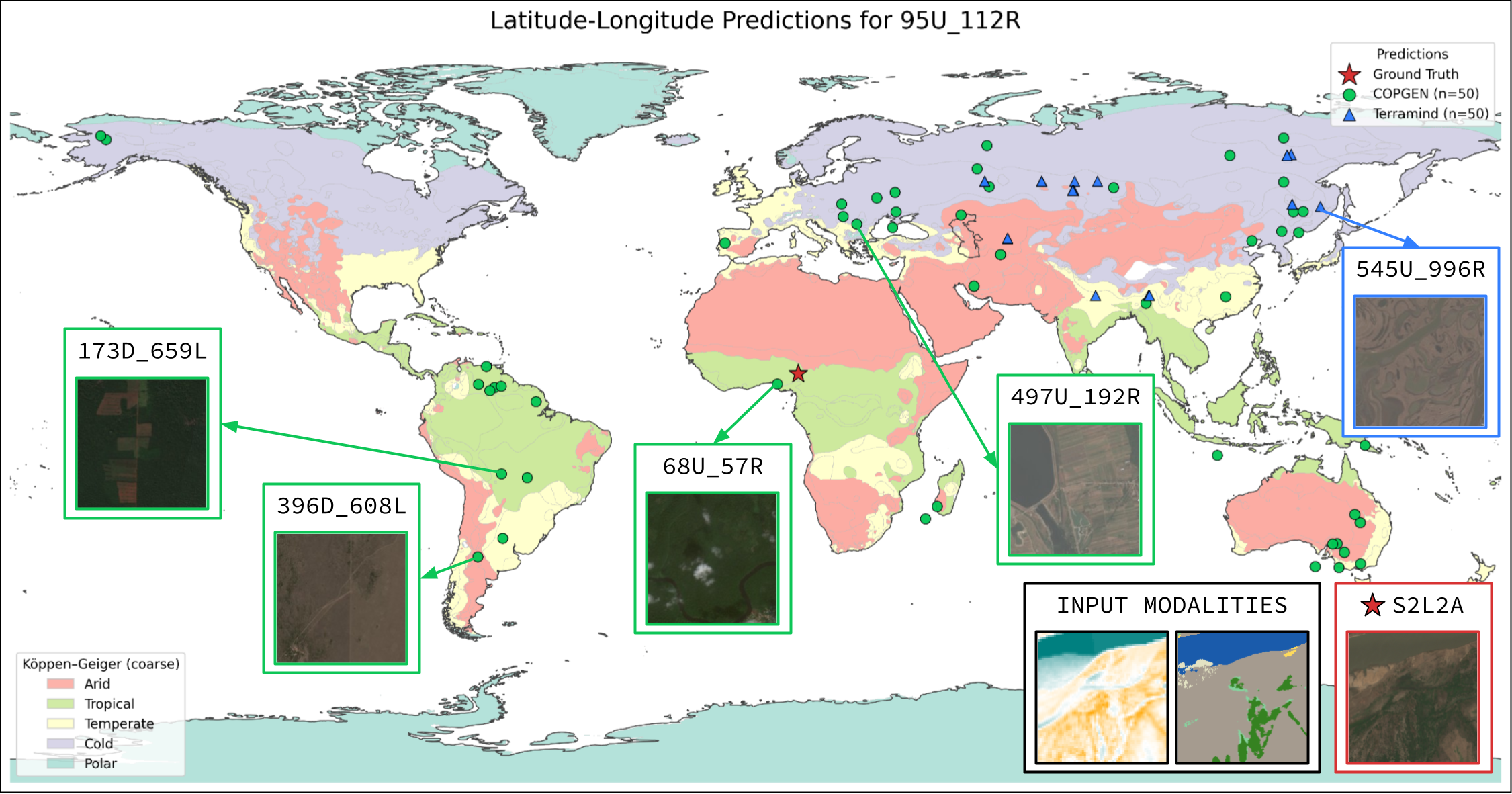
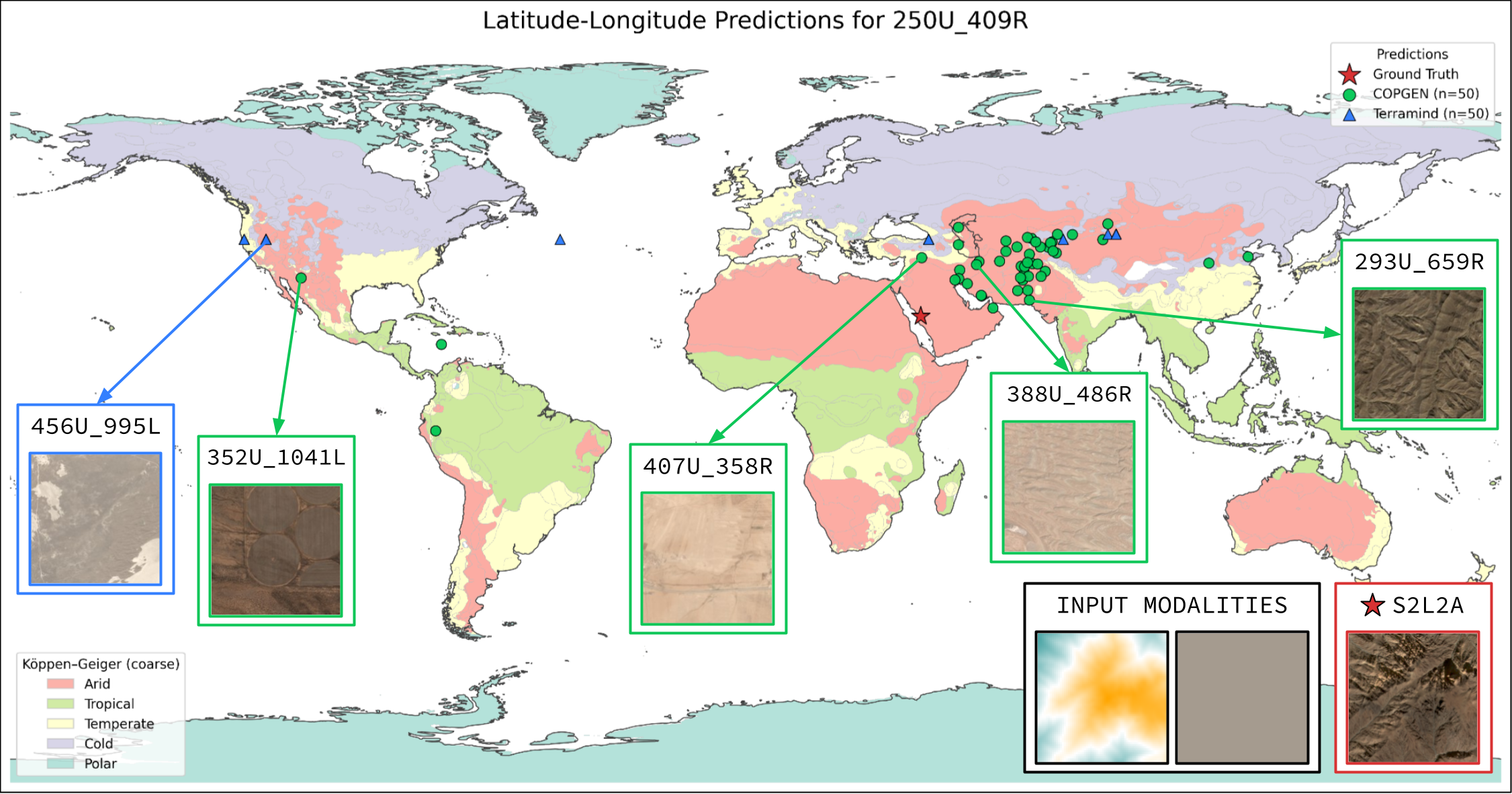
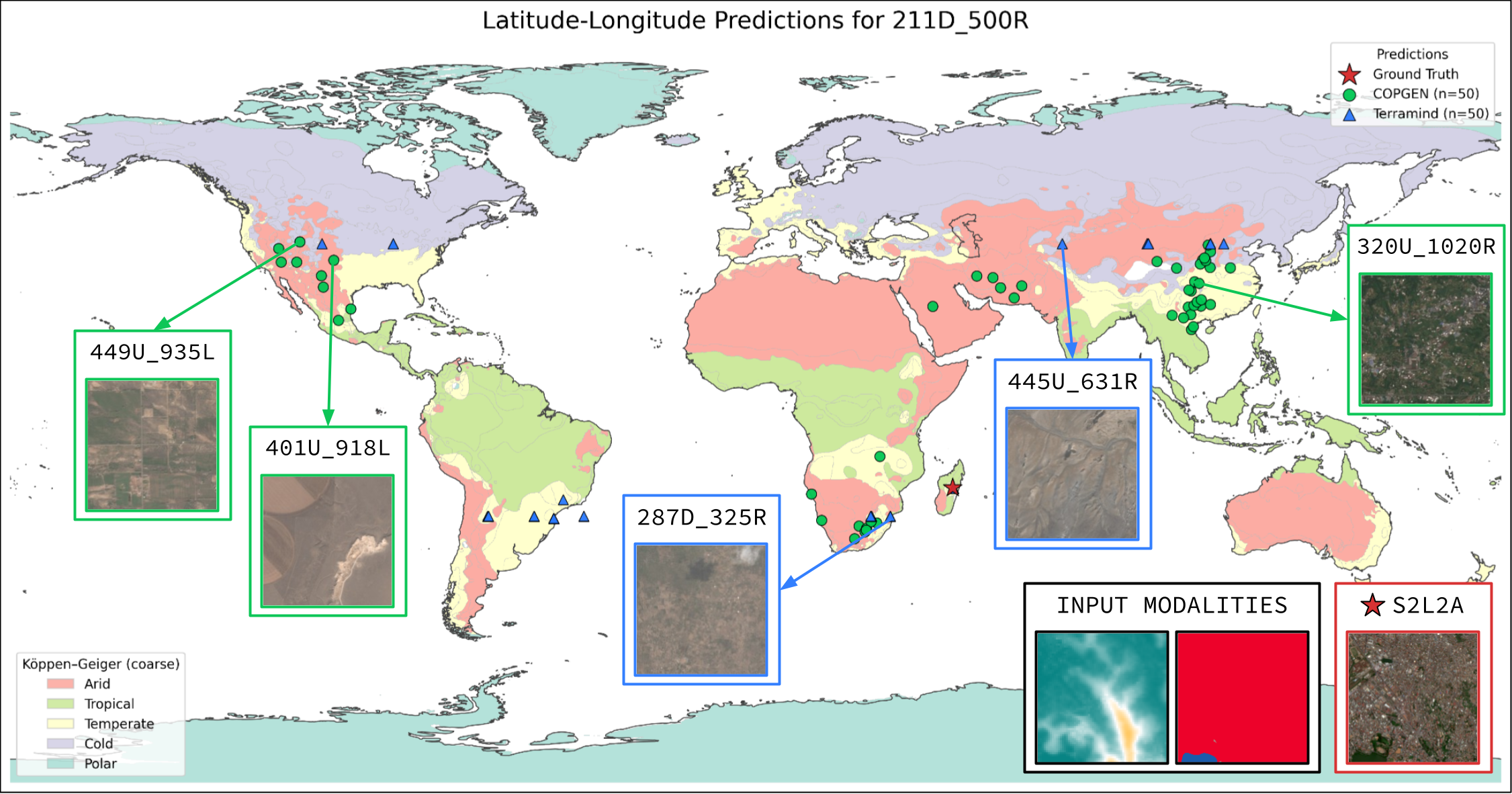
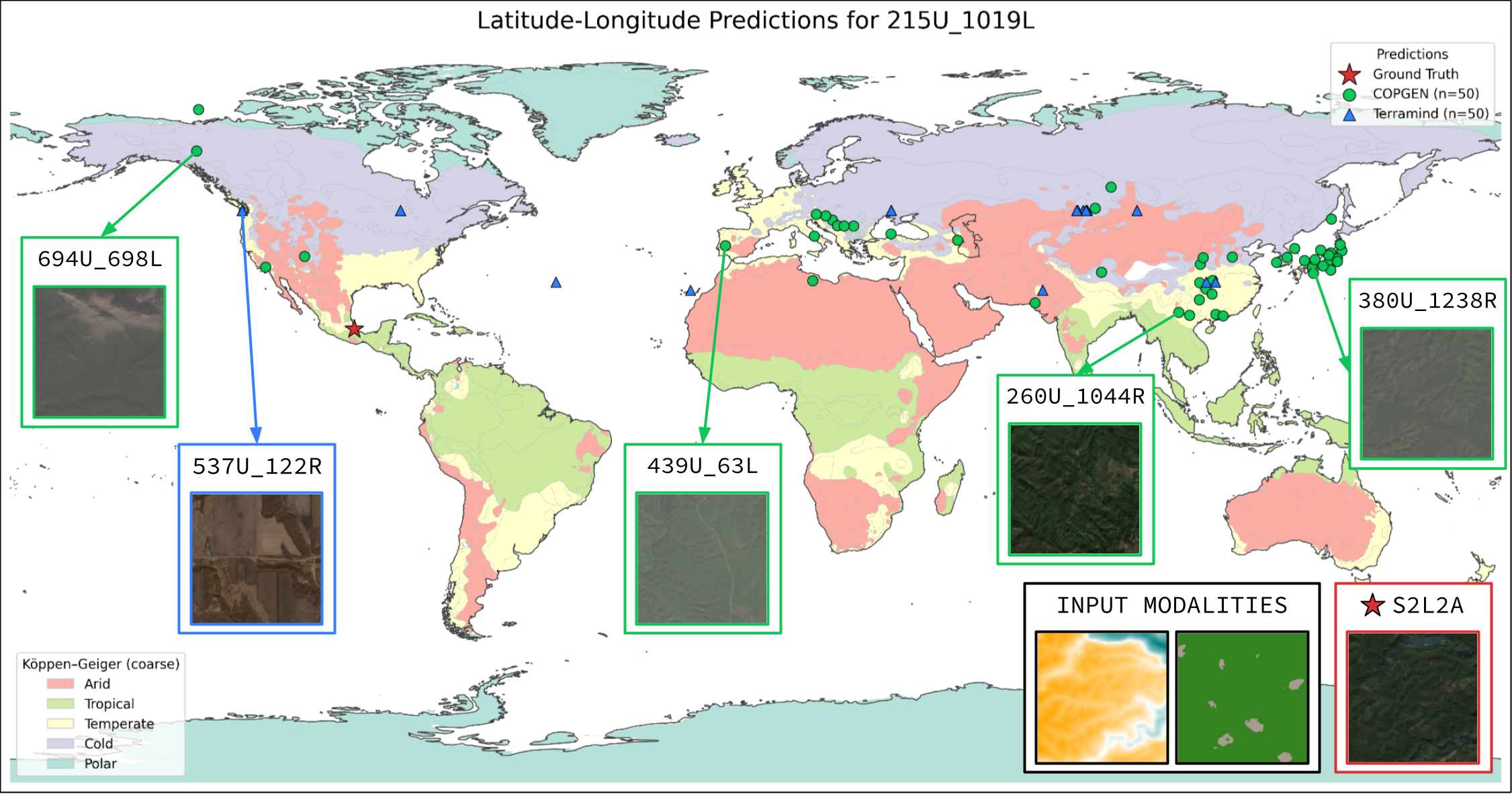
| LatLon | Mean km | 98.35 | 94.25 |
Table 1: Tile-Level Peak Capability Analysis. We report the oracle performance (best generation selected per tile) to demonstrate the upper bound of generation quality. Bold indicates the best result. † S2L2A not present among inputs. ‡ S2L1C not present among inputs.
We analyze the impact of removing individual conditioning modalities to reveal the physical couplings learned by the model.
| Target | Removed | Metric | COP-GEN | TerraMind |
|---|---|---|---|---|
| DEM | w/o LatLon | MAE | 47.44 | 140.01 |
| w/o LULC | MAE | 46.96 | 140.80 | |
| w/o S1RTC | MAE | 54.85 | 140.86 | |
| w/o S2L1C | MAE | 51.85 | 146.00 | |
| w/o S2L2A | MAE | 45.78 | 146.71 | |
| LULC | w/o LatLon | Top-1 Acc | 0.81 | 0.80 |
| w/o DEM | Top-1 Acc | 0.80 | 0.80 | |
| w/o S1RTC | Top-1 Acc | 0.79 | 0.80 | |
| w/o S2L1C | Top-1 Acc | 0.80 | 0.80 | |
| w/o S2L2A | Top-1 Acc | 0.80 | 0.80 | |
| S1RTC | w/o LatLon | MAE | 2.70 | 2.63 |
| w/o DEM | MAE | 2.75 | 2.63 | |
| w/o LULC | MAE | 2.76 | 2.63 | |
| w/o S2L1C | MAE | 2.70 | 2.64 | |
| w/o S2L2A | MAE | 2.68 | 2.62 | |
| S2L1C | w/o LatLon | MAE | 0.02 | 0.11 |
| w/o DEM | MAE | 0.02 | 0.11 | |
| w/o LULC | MAE | 0.02 | 0.11 | |
| w/o S1RTC | MAE | 0.02 | 0.11 | |
| w/o S2L2A | MAE | 0.06 | 0.12 | |
| S2L2A | w/o LatLon | MAE | 0.02 | 0.10 |
| w/o DEM | MAE | 0.02 | 0.10 | |
| w/o LULC | MAE | 0.02 | 0.10 | |
| w/o S1RTC | MAE | 0.02 | 0.10 | |
| w/o S2L1C | MAE | 0.07 | 0.10 | |
| LatLon | w/o DEM | Mean km | 210.54 | 90.67 |
| w/o LULC | Mean km | 188.70 | 95.50 | |
| w/o S1RTC | Mean km | 173.09 | 78.23 | |
| w/o S2L1C | Mean km | 193.43 | 138.83 | |
| w/o S2L2A | Mean km | 182.45 | 77.41 |
Table 2: Tile-Level Leave-One-Out Analysis. COP-GEN shows clear dominance in DEM reconstruction (MAE) and optical bands (S2L1C/S2L2A), while TerraMind demonstrates stronger localization capabilities (LatLon).
Oracle metrics measure peak single-sample fidelity; they cannot tell us whether the model's distribution of outputs matches the true distribution of plausible observations. We introduce a dedicated stochastic benchmark that directly compares 16 generated samples per cell against 16 real multi-temporal Sentinel-2 acquisitions across 489 geographically diverse cells, all conditioned on the same DEM and LULC inputs.
We evaluate two complementary streams: perceptual fidelity in three embedding spaces — 12-band spectral vectors, ResNet-50 RGB features, and LPIPS — using 1-NN accuracy, k-NN Precision/Recall and intra-set diversity; and physical consistency via MMD, per-band Wasserstein distance, and spectral range coverage.
| Stream | Metric | COP-GEN | TerraMind |
|---|---|---|---|
| Spectral (12-band reflectance) | |||
| 1-NN accuracy | 0.911 ± 0.075 | 0.985 ± 0.027 | |
| Precision (k=5) | 0.289 ± 0.348 | 0.483 ± 0.469 | |
| Recall (k=5) | 0.900 ± 0.264 | 0.028 ± 0.080 | |
| Intra-set distance | 0.455 ± 0.155 | 0.050 ± 0.015 | |
| RGB (ResNet-50) | |||
| 1-NN accuracy | 0.982 ± 0.031 | 0.998 ± 0.009 | |
| Precision (k=5) | 0.086 ± 0.220 | 0.119 ± 0.286 | |
| Recall (k=5) | 0.726 ± 0.370 | 0.001 ± 0.013 | |
| Intra-set distance | 13.39 ± 1.53 | 5.65 ± 0.76 | |
| LPIPS | |||
| Intra-set distance | 0.470 ± 0.046 | 0.287 ± 0.058 | |
| Physical consistency | |||
| MMD | 0.589 ± 0.287 | 1.149 ± 0.423 | |
| Wasserstein (mean, 12 bands) | 0.143 ± 0.109 | 0.117 ± 0.146 | |
| Spectral coverage | 0.629 ± 0.291 | 0.180 ± 0.144 | |
Table 3: Stochastic benchmark across 489 cells with 16 samples per source (real, COP-GEN, TerraMind). Mean ± std reported. Bold indicates the best result. For 1-NN accuracy and MMD lower is better; for Precision, Recall, and Coverage higher is better. Intra-set distance is a diversity measure (real spectral intra-set distance = 0.214, sitting between the two models).
TerraMind's advantages lie in metrics that reward proximity to the distribution centre (precision = 0.483, Wasserstein = 0.117): each sample lands near the densest region of the real manifold — a consequence of near-deterministic generation rather than superior stochastic modelling. COP-GEN trades a small amount of per-sample precision for distribution-level coverage, achieving 0.589 MMD (≈half of TerraMind's 1.149) and 63% spectral range coverage versus 18%. The same pattern holds across all three feature spaces, indicating that diversity collapse is a fundamental property of deterministic generators under one-to-many cross-modal mappings rather than an artefact of any single embedding.
Reproducibility. The full benchmark — 7,824 acquisitions per source, with canonical SHA-256 seed subsampling and pinned dependencies — is released on HuggingFace and reproducible end-to-end with a single command in ~20 minutes on a single A100 GPU.
We present COP-GEN, the first multimodal latent diffusion transformer that learns the joint distribution of heterogeneous Earth observation data at native spatial resolutions. Resolution-aware tokenisation, modality-specific latent encoders, and independent diffusion timesteps enable flexible any-to-any conditional generation, zero-shot modality translation, and spectral band infilling — all without task-specific retraining or aggressive resampling.
In contrast to deterministic approaches, COP-GEN captures the one-to-many physical mappings intrinsic to remote sensing: it maintains strong peak fidelity while producing diverse, physically plausible realisations that respect topography, land cover, and spectral signatures, and systematically narrows its output distribution as conditioning becomes more informative — modulating variability rather than collapsing toward the conditional mean.
This work also reframes how generative EO models should be evaluated. Pointwise metrics favour deterministic solutions and hide diversity collapse: on our stochastic benchmark a near-deterministic competitor wins per-sample precision (0.483 spectral) yet achieves only 2.8% recall and 18% spectral range coverage, whereas COP-GEN reaches 90% and 63% respectively — a gap that single-reference metrics cannot reveal. We release this benchmark to standardise distribution-level evaluation, and identify temporal sequence modelling, scaling to higher spatial resolutions, and hybrid deterministic–stochastic systems as natural extensions of this work.
@article{espinosa2026copgen,
title={COP-GEN: Latent Diffusion Transformer for Copernicus Earth Observation Data},
author={Espinosa, Miguel and Gmelich Meijling, Eva and Marsocci, Valerio and Crowley, Elliot J. and Czerkawski, Mikolaj},
journal={arXiv preprint},
year={2026}
}