Miguel Espinosa

I am a PhD student at the University of Edinburgh under the SENSE CDT program, and part of the BayesWatch research group, advised by Dr. Elliot J. Crowley.
My current research lies in the intersection of Machine Learning (Computer Vision) and Earth Observation fields.
My research interests are:
- Diffusion models for Earth Observation.
- Self-supervised methods for data fusion. Learning semantic representations of satellite images.
- Adapting foundational models for large domain shift.
selected publications
-
 COP-GEN-Beta: Unified Generative Modelling of COPernicus Imagery ThumbnailsMiguel Espinosa, Valerio Marsocci, Yuru Jia, and 2 more authorsCVPRW, 2025
COP-GEN-Beta: Unified Generative Modelling of COPernicus Imagery ThumbnailsMiguel Espinosa, Valerio Marsocci, Yuru Jia, and 2 more authorsCVPRW, 2025In remote sensing, multi-modal data from various sensors capturing the same scene offers rich opportunities, but learning a unified representation across these modalities remains a significant challenge. Traditional methods have often been limited to single or dual-modality approaches. In this paper, we introduce COP-GEN-Beta, a generative diffusion model trained on optical, radar, and elevation data from the Major TOM dataset. What sets COP-GEN-Beta apart is its ability to map any subset of modalities to any other, enabling zero-shot modality translation after training. This is achieved through a sequence-based diffusion transformer, where each modality is controlled by its own timestep embedding. We extensively evaluate COP-GEN-Beta on thumbnail images from the Major TOM dataset, demonstrating its effectiveness in generating high-quality samples. Qualitative and quantitative evaluations validate the model’s performance, highlighting its potential as a powerful pre-trained model for future remote sensing tasks.
@article{espinosa2025copgenbeta, author = {Espinosa, Miguel and Marsocci, Valerio and Jia, Yuru and Crowley, Elliot J. and Czerkawski, Mikolaj}, title = {COP-GEN-Beta: Unified Generative Modelling of COPernicus Imagery Thumbnails}, year = {2025}, journal = {CVPRW}, institution = {University of Edinburgh, European Space Agency, KU Leuven, Asterisk Labs}, url = {https://arxiv.org/abs/2504.08548}, } -
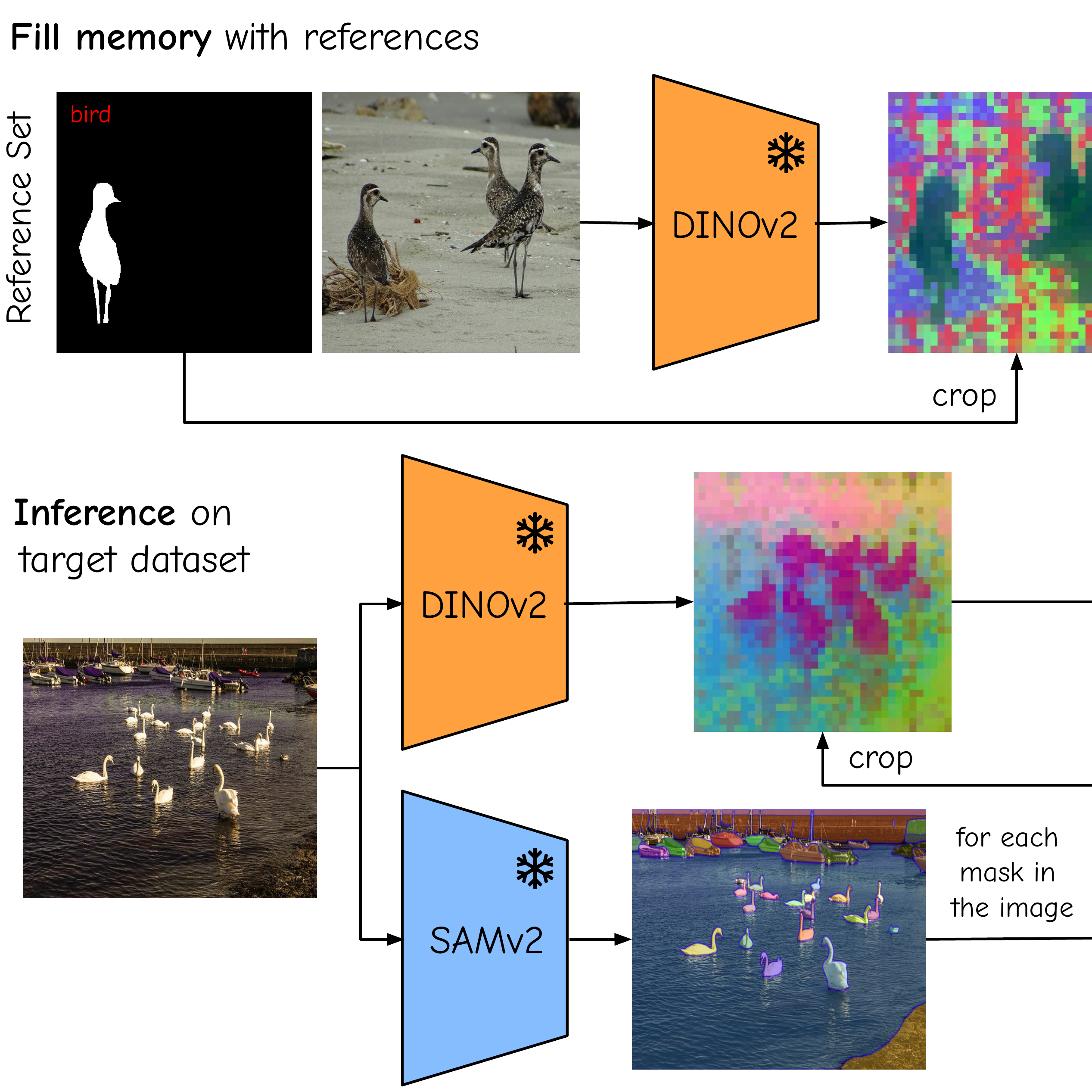 No Time to Train: A Simple Approach to Zero-Shot Modality TranslationMiguel Espinosa, Chenhongyi Yang, Linus Ericsson, and 2 more authorsarXiv, 2025
No Time to Train: A Simple Approach to Zero-Shot Modality TranslationMiguel Espinosa, Chenhongyi Yang, Linus Ericsson, and 2 more authorsarXiv, 2025The performance of image segmentation models has historically been constrained by the high cost of collecting large-scale annotated data. The Segment Anything Model (SAM) alleviates this original problem through a promptable, semantics-agnostic, segmentation paradigm and yet still requires manual visual-prompts or complex domain-dependent prompt-generation rules to process a new image. Towards reducing this new burden, our work investigates the task of object segmentation when provided with, alternatively, only a small set of reference images. Our key insight is to leverage strong semantic priors, as learned by foundation models, to identify corresponding regions between a reference and a target image. We find that correspondences enable automatic generation of instance-level segmentation masks for downstream tasks and instantiate our ideas via a multi-stage, training-free method incorporating (1) memory bank construction; (2) representation aggregation and (3) semantic-aware feature matching. Our experiments show significant improvements on segmentation metrics, leading to state-of-the-art performance on COCO FSOD (36.8% nAP), PASCAL VOC Few-Shot (71.2% nAP50) and outperforming existing training-free approaches on the Cross-Domain FSOD benchmark (22.4% nAP).
@article{espinosa2025notimetotrain, author = {Espinosa, Miguel and Yang, Chenhongyi and Ericsson, Linus and McDonagh, Steven and Crowley, Elliot J.}, title = {No Time to Train: A Simple Approach to Zero-Shot Modality Translation}, year = {2025}, journal = {arXiv}, institution = {University of Edinburgh}, url = {https://arxiv.org/abs/2507.02798}, } -
 There is no SAMantics! Exploring SAM as a Backbone for Visual Understanding TasksMiguel Espinosa, Chenhongyi Yang, Linus Ericsson, and 2 more authorsarXiv, 2024
There is no SAMantics! Exploring SAM as a Backbone for Visual Understanding TasksMiguel Espinosa, Chenhongyi Yang, Linus Ericsson, and 2 more authorsarXiv, 2024The Segment Anything Model (SAM) was originally designed for label-agnostic mask generation. Does this model also possess inherent semantic understanding, of value to broader visual tasks? In this work we follow a multi-staged approach towards exploring this question. We firstly quantify SAM’s semantic capabilities by comparing base image encoder efficacy under classification tasks, in comparison with established models (CLIP and DINOv2). Our findings reveal a significant lack of semantic discriminability in SAM feature representations, limiting potential for tasks that require class differentiation. This initial result motivates our exploratory study that attempts to enable semantic information via in-context learning with lightweight fine-tuning where we observe that generalisability to unseen classes remains limited. Our observations culminate in the proposal of a training-free approach that leverages DINOv2 features, towards better endowing SAM with semantic understanding and achieving instance-level class differentiation through feature-based similarity. Our study suggests that incorporation of external semantic sources provides a promising direction for the enhancement of SAM’s utility with respect to complex visual tasks that require semantic understanding.
@article{espinosa2024samantics, author = {Espinosa, Miguel and Yang, Chenhongyi and Ericsson, Linus and McDonagh, Steven and Crowley, Elliot J.}, title = {There is no SAMantics! Exploring SAM as a Backbone for Visual Understanding Tasks}, year = {2024}, journal = {arXiv}, institution = {University of Edinburgh}, url = {https://arxiv.org/abs/2411.15288}, } -
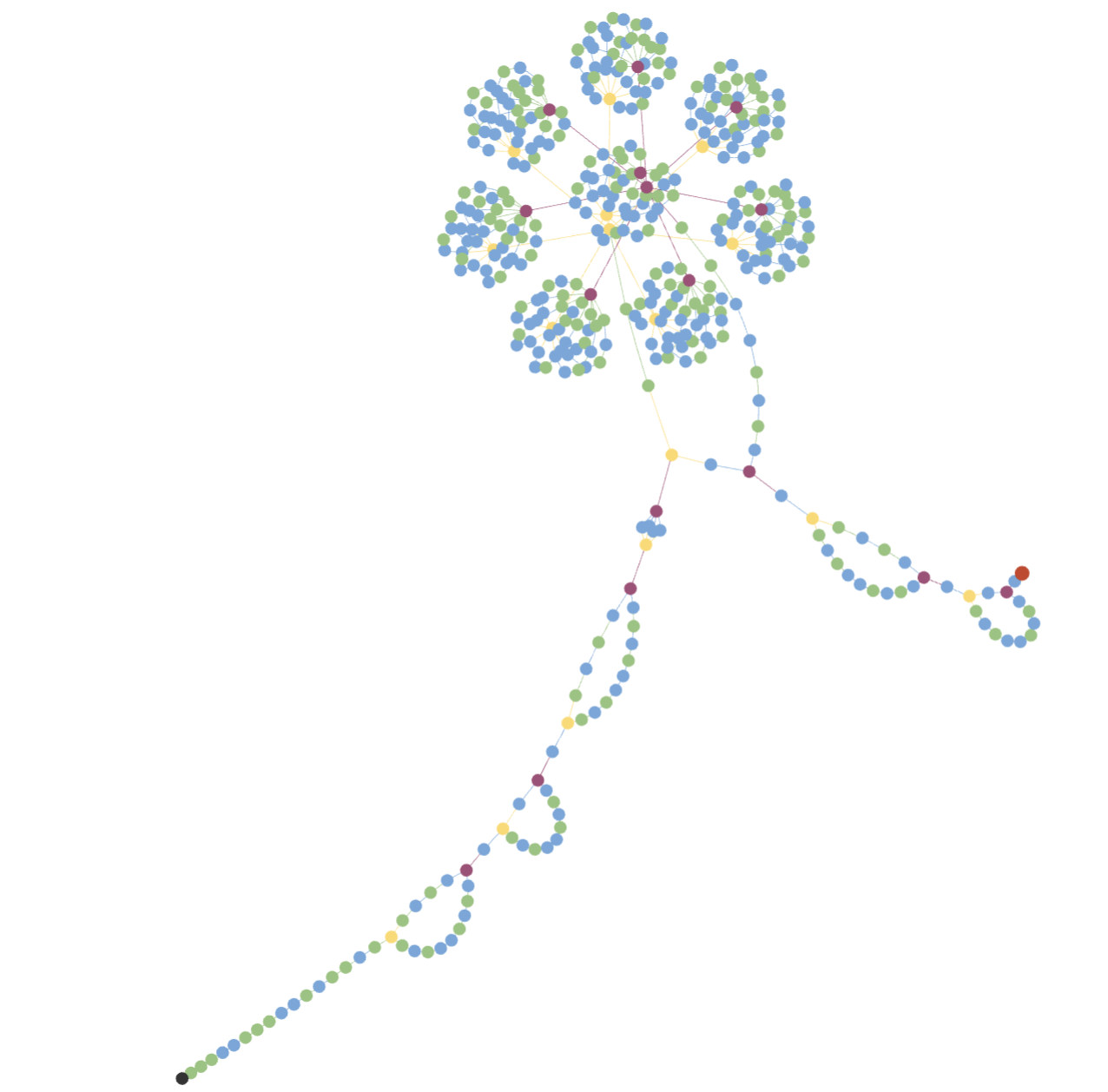 einspace: Searching for Neural Architectures from Fundamental OperationsLinus Ericsson, Miguel Espinosa, Chenhongyi Yang, and 5 more authorsNeurIPS, 2024
einspace: Searching for Neural Architectures from Fundamental OperationsLinus Ericsson, Miguel Espinosa, Chenhongyi Yang, and 5 more authorsNeurIPS, 2024Neural architecture search (NAS) finds high performing networks for a given task. Yet the results of NAS are fairly prosaic; they did not e.g. create a shift from convolutional structures to transformers. This is not least because the search spaces in NAS often aren’t diverse enough to include such transformations a priori. Instead, for NAS to provide greater potential for fundamental design shifts, we need a novel expressive search space design which is built from more fundamental operations. To this end, we introduce einspace, a search space based on a parameterised probabilistic context-free grammar. Our space is versatile, supporting architectures of various sizes and complexities, while also containing diverse network operations which allow it to model convolutions, attention components and more. It contains many existing competitive architectures, and provides flexibility for discovering new ones. Using this search space, we perform experiments to find novel architectures as well as improvements on existing ones on the diverse Unseen NAS datasets. We show that competitive architectures can be obtained by searching from scratch, and we consistently find large improvements when initialising the search with strong baselines. We believe that this work is an important advancement towards a transformative NAS paradigm where search space expressivity and strategic search initialisation play key roles.
@article{ericsson2024einspace, author = {Ericsson, Linus and Espinosa, Miguel and Yang, Chenhongyi and Antoniou, Antreas and Storkey, Amos and Cohen, Shay B. and McDonagh, Steven and Crowley, Elliot J.}, title = {einspace: Searching for Neural Architectures from Fundamental Operations}, year = {2024}, journal = {NeurIPS}, institution = {University of Edinburgh}, url = {https://arxiv.org/abs/2405.20838}, } -
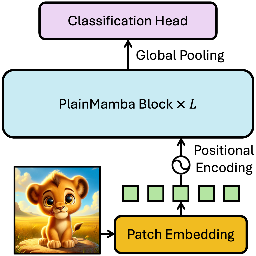 PlainMamba: Improving Non-Hierarchical Mamba in Visual RecognitionChenhongyi Yang, Zehui Chen, Miguel Espinosa, and 4 more authorsBMVC, 2024
PlainMamba: Improving Non-Hierarchical Mamba in Visual RecognitionChenhongyi Yang, Zehui Chen, Miguel Espinosa, and 4 more authorsBMVC, 2024We present PlainMamba: a simple non-hierarchical state space model (SSM) designed for general visual recognition. The recent Mamba model has shown how SSMs can be highly competitive with other architectures on sequential data and initial attempts have been made to apply it to images. In this paper, we further adapt the selective scanning process of Mamba to the visual domain, enhancing its ability to learn features from two-dimensional images by (i) a continuous 2D scanning process that improves spatial continuity by ensuring adjacency of tokens in the scanning sequence, and (ii) direction-aware updating which enables the model to discern the spatial relations of tokens by encoding directional information. Our architecture is designed to be easy to use and easy to scale, formed by stacking identical PlainMamba blocks, resulting in a model with constant width throughout all layers. The architecture is further simplified by removing the need for special tokens. We evaluate PlainMamba on a variety of visual recognition tasks including image classification, semantic segmentation, object detection, and instance segmentation. Our method achieves performance gains over previous non-hierarchical models and is competitive with hierarchical alternatives. For tasks requiring high-resolution inputs, in particular, PlainMamba requires much less computing while maintaining high performance. Code and models are available at https://github.com/ChenhongyiYang/PlainMamba.
@article{yang_2024_3_plainmamba, author = {Yang, Chenhongyi and Chen, Zehui and Espinosa, Miguel and Ericsson, Linus and Wang, Zhenyu and Liu, Jiaming and Crowley, Elliot J.}, title = {PlainMamba: Improving Non-Hierarchical Mamba in Visual Recognition}, year = {2024}, journal = {BMVC}, institution = {University of Edinburgh}, url = {https://arxiv.org/abs/2403.17695}, } -
 Generate Your Own Scotland: Satellite Image Generation Conditioned on MapsMiguel Espinosa, and Elliot J. CrowleyNeurIPS Workshop on Diffusion Models, 2023
Generate Your Own Scotland: Satellite Image Generation Conditioned on MapsMiguel Espinosa, and Elliot J. CrowleyNeurIPS Workshop on Diffusion Models, 2023Despite recent advancements in image generation, diffusion models still remain largely underexplored in Earth Observation. In this paper we show that state-of-theart pretrained diffusion models can be conditioned on cartographic data to generate realistic satellite images. For this purpose, we provide two large datasets of paired maps and satellite views over the region of Mainland Scotland and the Central Belt. We train a ControlNet model and qualitatively evaluate the results, demonstrating that both image quality and map fidelity are possible. Additionally, we explore its use for the reconstruction of historical maps. Finally, we provide some insights on the opportunities and challenges of applying these models for remote sensing.
@article{espinosa_2023_8_mapsat, author = {Espinosa, Miguel and Crowley, Elliot J.}, title = {Generate Your Own Scotland: Satellite Image Generation Conditioned on Maps}, year = {2023}, journal = {NeurIPS Workshop on Diffusion Models}, institution = {University of Edinburgh}, url = {https://arxiv.org/abs/2308.16648}, }





